Documentation
Table of Content
Welcome to the Flowy documentation section! Here, you will find a wealth of information and resources to help you get the most out of the Flowy platform. Whether you are just starting out with Flowy or are an experienced user, you will find everything you need to know about how to build, deploy and manage workflow automation solutions using Flowy.
The documentation has been split into separate documents due to its size:
- Introduction
- Installation
- Plug-in: explains how to develop own plug-ins
- Permissions: describes the internal permission system
- Processes: guidance on workflows (defined within Flowy)
- Services: information about the Flowy services
- Steps: provide details on steps
- Triggers: provide details on triggers that start processes
- Credentials: explore the mechanisms behind Flowy's credential management system
- Objects: provide insights on the internal structure and workings
- Templates & Translations: explains how templates and translations can be used
- Validations: explains how ensure the integrity of the data that flows into the system
- Configuration: documents how to configure Flowy
- Startup: gives guidance on how to correctly startup Flowy
- Docker: describes how to build and/or use docker images
- Set-up on AWS using EC2: provides an guide on how to set up Flowy using AWS and EC2 instances
- Authentication for Flowy processes: explains how to log in in order to trigger authenticated Flowy processes
- Flowy Util: CLI tool for an easy and efficient integration into CI and CD automation
- Troubleshooting: provides help in case issues occur
- Versioning control: details on how Flowy addresses version control
- Limitations: provide an overview of Flowy's limitations
- Definition of Terms: an overview of the terms used throughout this page
Introduction
Platform Overview
Flowy is a platform designed to be highly scalable and reliable. It is designed following Hexagonal Architecture principles and clearly separates between the user-side, business logic respective server side.
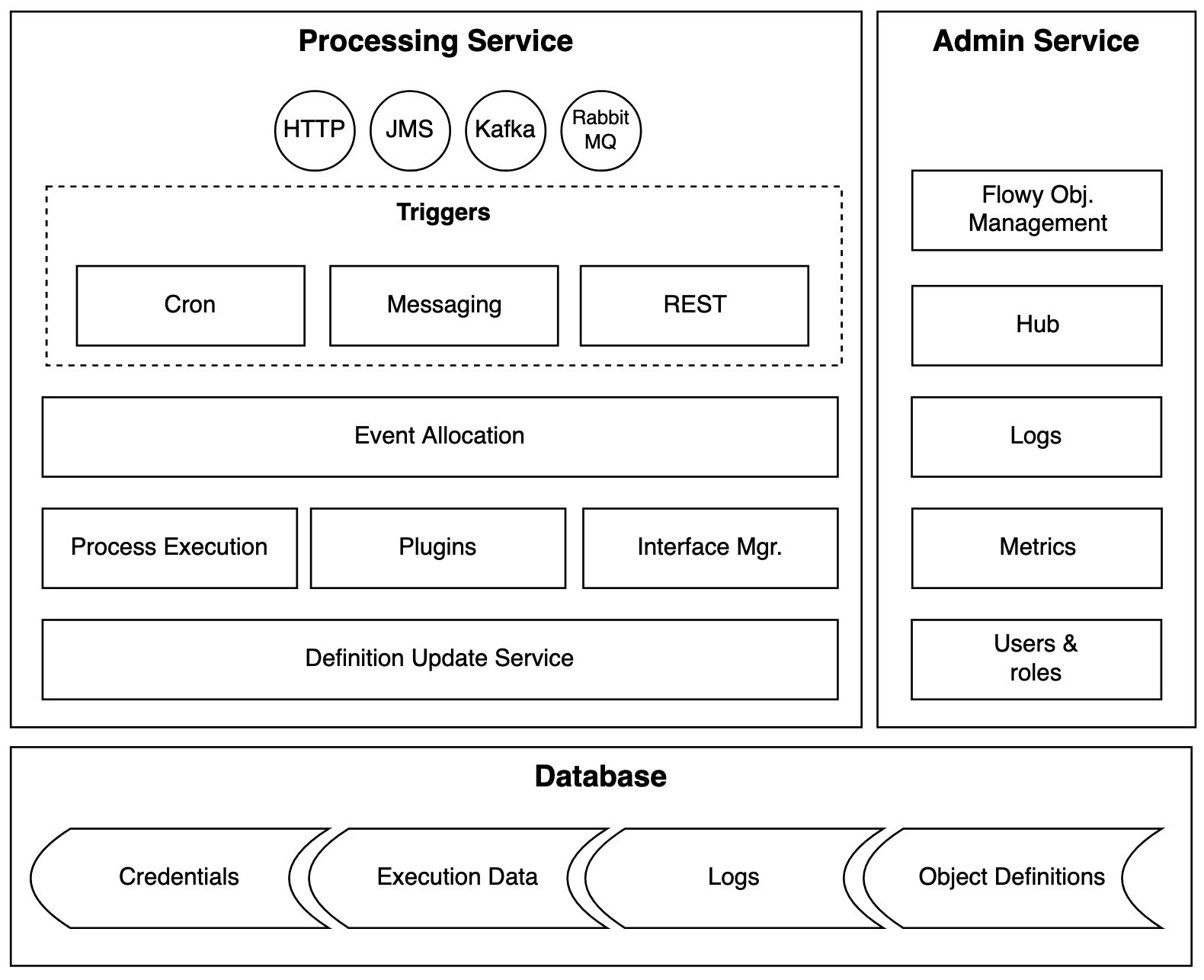
Flowy is operated using 3 environment types:
Event-Driven Workflows in Flowy
Each request starts either by an user interaction (i.e. by a REST request) or by automatic trigger (i.e. by a time based condition). In each of this cases an event gets created and later processed following the pre-defined business logic.
At its core, each process within Flowy consists of:
- trigger: the firing condition. Could be i.e. an action by an user or a time based automation (i.e. every midnight)
- event: once any kind of trigger has fired, it creates an event entry which is used to track its processing
- process: this is the logic and behaviour that triggers actions and reacts based on their result
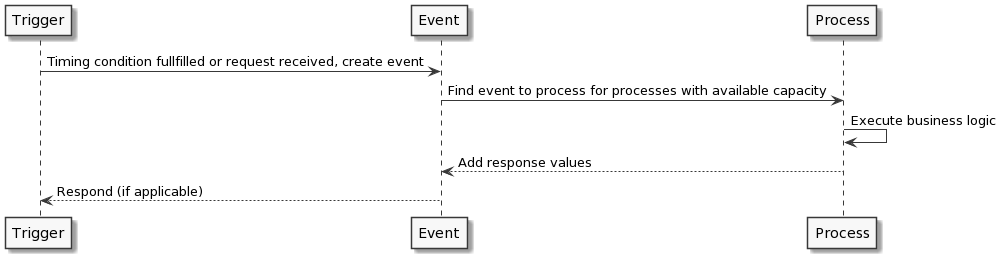
Flowy processes are always executed on the processing service, which is described in the services section. Please refer to Flowy Processes to learn more about the process respective Flowy Steps for information on the steps they include.
Flowy Processes
Each process in Flowy represents a modular, deterministic workflow that reacts to inputs and transforms data through clearly defined steps. A process consists of a sequence of operations including scripting, conditional logic, sub-process execution, and interactions with external systems.
At a high level, a Flowy process behaves like a lightweight state machine:
- It is triggered by an external event (such as a REST API request)
- It operates on a shared variable context called the Process Cache, using variables prefixed with $
- It executes typed steps, each with a clearly defined purpose—transforming data, accessing databases, or handling errors
- It progresses through conditional paths, sub-process calls, or iterations until completion
Every process is designed to be stateless from the outside perspective. Its state is entirely encapsulated by the variable cache and persisted through step logs, making debugging and recovery both deterministic and traceable.
Design principles:
- Keep processes small and composable
- Structure logic as a clear flow: inputs → transformation → outputs
- Leverage process composition for reusability and separation of concerns
Flowy is built to encourage modular design. Instead of duplicating logic across processes, you can define reusable patterns that enhance maintainability and testability. Encapsulate commonly used logic—such as validating companies, creating audit logs, or preparing translations—in dedicated sub-processes and invoke them via the Execute Process step. This makes your main process easier to read and keeps logic isolated.
Use the built-in Templates and Translations objects to externalize UI content or localized messages. This allows you to:
- Swap out messages without touching business logic
- Reuse consistent formatting across steps
Instead of hardcoding URLs or credentials, define them centrally using:
- Settings: for environment-specific values
- Credentials: for API keys, database access, and other sensitive data
Variables and Process Cache
Variables can be used to temporarily store data during runtime. A variable can be declared in Flowy using $. followed by the variable name.
During execution, variables are stored in-memory to the so called Process Cache. By default, the cache gets persisted to the database as part of each step log. This behavior can be disabled to improve performance and reduce database size.
The variables can be manipulated or even removed (through the Unset Variables step) at runtime. The cache is fully accessible to all steps of an process.
Variables expected to contain files (i.e., handled via FTP, IMAP, Image, PDF, S3, or ZIP) are not persisted; for these, the cache will display only their size.
For safety reasons, variables should not be used for security related data. The use of credentials is recommended in such cases.
Info
Java imposes a limit on the maximum size of data that can be stored in a variable. This limit depends on the environment and available heap memory. Based on experience, we recommend keeping variable sizes below 15 MB to ensure optimal performance and stability.
Note that the system automatically injects execution parameters into the $.flowy variable at runtime.
By default, the following fields are available in the cache for every step:
$.flowy.eventId
$.flowy.processName
$.flowy.instanceId
$.flowy.environmentName
If a step simply fails, no additional fields are added to the cache.
However, the following fields are added to the cache when the event handler is triggered and starts a process:
$.flowy.triggerProcessId
$.flowy.failedEventId
$.flowy.listenStatus
$.flowy.stepExceptions
$.flowy.eventException.exceptionName
$.flowy.eventException.exceptionMessage
$.flowy.eventException.exceptionStackTrace
$.flowy.output
Development Approach
The typical development must happen in the following order:
- Start with the creation of a process: It is sufficient to implement only a small part of the later functionality at first.
- Creation of triggers: for testing purposes it is convenient to create a cron trigger and trigger it manually when needed. Alternatively, a REST trigger can be created and triggered through curl, Insomnia REST, Postman or similar tools.
- Creation of credentials, templates, translations and validations as needed along with the necessary updates on trigger and processes.
This intentionally iterative approach quickly leads to usable results.
There is a strict demarcation line between configuration data and business logic. This enables the effective movement of workflow through environments (i.e. development, testing, production). As this happens, they get tested. By the time they reach production, you have tested both the workflow itself and the ability to deploy as well as the support processes around it.
Configuration data includes the following object types:
- Credentials
- Settings
- Templates
- Translations
Business logic is implemented with the following object types:
- Entity
- Libraries
- Modules
- Plugins
- Processes
- Triggers
- Validations
This approach makes it easy to roll out existing workflows i.e. to new environments as it’s just a matter of configuration.
Version control
Flowy offers native support for versioning, ensuring that users can easily manage and track different versions of their projects. This feature is crucial for collaboration and maintaining a clear history of changes. For an in-depth understanding of how versioning works in Flowy and to leverage its full potential, please refer to the detailed documentation available on our separate page: versioning in Flowy.